Science and Technology Indicators for Norway 2017
Time series and international data are also included.
Send us a link
Time series and international data are also included.
We wish to answer this question: If you observe a ‘significant’ p -value after doing a single unbiased experiment, what is the probability that your result is a false positive?

When statistical fudging is buried in the way data are sliced and diced after the fact or put through tortured analysis in a search for significant results.

According to its developers, Statcheck gets it right in more than 95% of cases. Some outsiders still aren’t convinced.
"It is not statistics that is broken, but how it is applied to science." - S. Goodman
When Dutch researchers developed an open-source algorithm designed to flag statistical errors in psychology papers, it received mixed reaction from the research community.

Comments on "Redefine statistical significance"
Researchers who want professorships are sometimes driven to publish suspect findings.

Scientists hit back at a proposal to make it tougher to call findings statistically significant.
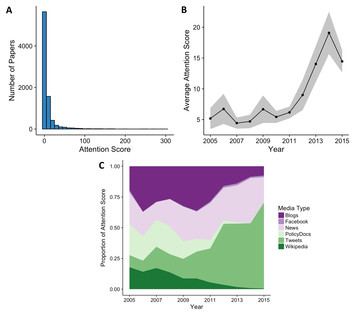
Published P-values provide a window into the global enterprise of medical research. The aim of this study was to use the distribution of published P-values to estimate the relative frequencies of null and alternative hypotheses and to seek irregularities suggestive of publication bias.
The case for, and against, redefining "statistical significance."

One of scientists’ favourite statistics — the P value — should face tougher standards, say leading researchers.
Proposal to change widely accepted p-value threshold stirs reproducibility debate.

Significance thresholds and the crisis of unreplicable research
Today we’re rolling out new features in Sheets that make it even easier for you to visualize and share your data, and find insights your teams can act on.

"When someone is honestly 55 percent right, that’s very good and there’s no use wrangling. And if someone is 60 percent right, it’s wonderful, it’s great luck, and let him thank God."
Take proposals that should never have been submitted out of the figures, and the chances of winning funding look a lot brighter.

Significance thresholds and the crisis of unreplicable research
This is the second part in a series on how we edit science, looking at hypothesis testing, the problem of p-hacking and how the peer review process works.
Are we leaving behind the age of statistics, and entering a new age of big data controlled by private companies?

Academic psychology and medical testing are both dogged by unreliability. The reason is clear: we got probability wrong.
The replication crisis in science is largely attributable to a mismatch in our expectations of how often findings should replicate and how difficult it is to actually discover true findings in certain fields.
The persistence of poor methods results partly from incentives that favor them, leading to the natural selection of bad science. This dynamic requires no conscious strategizing - no deliberate cheating nor loafing - by scientists, only that publication is a principle factor for career advancement.
On the many ways to say the same thing.

The problem with p-values.

Ridding science of shoddy statistics will require scrutiny of every step, not merely the last one.

H-index, citations, self-citations and other figures about Switzerland, based on Scopus data.